Following are my notes for the video lectures of IIT-K, NPTEL, NLP course. (Not orgnanized properly, will do them soon.)
“Language is the foundation of civilization. It is the glue that holds a people together. It is the first weapon drawn in a conflict.” - Arrival (2016).
Problems in NLP :
- Ambiguity
- Open Domain
- Relation between Entities
- Impractical GoalsWhy is language processing hard ?
- Lexical Ambiguity :Input : “Will Will Smith play the role of Will Wise in Will the wise ?”
Output using spaCy :
Will - will ( MD ) VERB
Will - will ( VB ) VERB —> ( NNP ) PROPN
Smith - smith ( NNP ) PROPN
play - play ( VB ) VERB
the - the ( DT ) DET
role - role ( NN ) NOUN
of - of ( IN ) ADP
Will - will ( NNP ) PROPN
Wise - wise ( NNP ) PROPN
in - in ( IN ) ADP
Will - will ( NNP ) PROPN
the - the ( DT ) DET
wise - wise ( JJ ) ADJ
? - ? ( . ) PUNCT
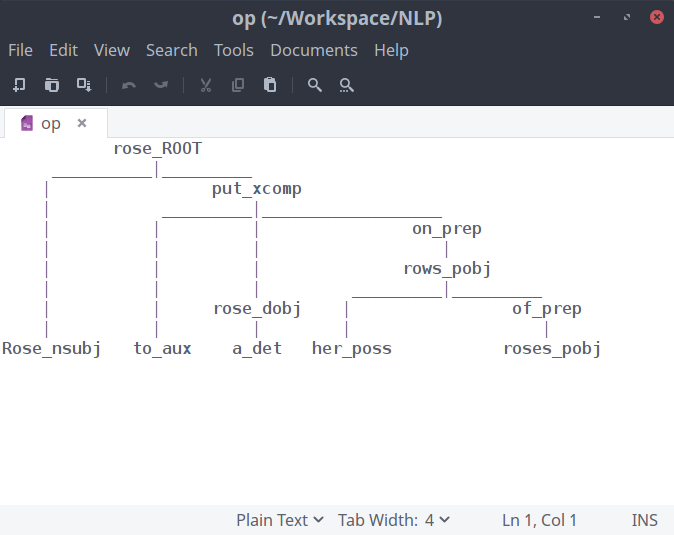
Input : “Rose rose to put a rose on her rows of roses.”
Output using spaCy :
Rose - rose ( NNP ) PROPN
rose - rise ( VBD ) VERB
to - to ( TO ) PART
put - put ( VB ) VERB
a - a ( DT ) DET
rose - rose ( NN ) NOUN
on - on ( IN ) ADP
her - her ( PRP$ ) ADJ
rows - row ( NNS ) NOUN
of - of ( IN ) ADP
roses - rose ( NNS ) NOUN
. - . ( . ) PUNCT
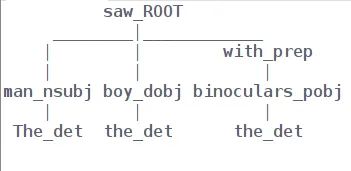
- Structural AmbiguityInput : “The man saw the boy with the binoculars”
Output using spaCy :
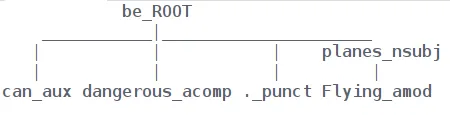
Input : “Flying planes can be dangerous.”
Output using spaCy :
- Imprecise and Vague“It is very warm here” - The condition of being ‘Warm’ isn’t associated with a fixed temperature range and can vary from person to person depending upon there threshold for warmness.
“Q : Did your mom call your sister last night?”
“A : I’m sure she must have” - Here the answer doesn’t convey the accurate information and is just a prediction, which can be true or false. Hence, it doesn’t provide the questionnaire with useful information.
A classic example to demonstrate ambiguity “I made her a duck.”

Catalan number : Number of parses generated for a sentence given to a parser as an input.
- Non Standard English / Informal English
- Segmentation Issues
- Idioms / Phrases / Pop culture references
- Neologisms / New words
- New senses of words
- Named Entities
Empirical Laws
Function words : serve as important elements to the structure of sentences and contribute very less to the lexical meaning of the sentences.
eg. prepositions, pronouns, auxiliary verbs, conjunctions, grammatical articles, particles, etc. [Closed-class words]
Content words : Convey information
Type-Token distinction : distinction separating a concept from the objects which are particular instances of the concept. Distinguishing between similar tokens on the basis of their type. “Will Will Smith play the role of Will Wise in Will the wise ?”
Here both the tokens although look similar but differ vastly with respect to their tokens.
Type/Token ratio : the ratio of the number of different words to the number of running words in the corpus. It indicates how often, on average, a new ‘word form’ appears in the text corpus.
Heap’s Law : |V| = KN^n
Number of unique token-types increase to square root of the corpus size.
Text Processing
Tokenization : segmentation of a string into words
Sentence segmentation : Boundary detection for a sentence. This task is challenging due to the fact that punctuation marks like dot (.) which usually represents the termination of sentences can also represents certain abbreviations or initials, which certainly do not indicate an end of the sentence. A binary classifier can built to decide the two possible out comes ie. a sentence termination and not a sentence termination. To build this sentence terminator we can use decision tree, some hand coded rules (cringe).
Word Tokenization : Apostrophe, Named Entities, Abbreviations.
**Handling Hyphens **: End of the line, lexical, sententially determined
Normalization
**Case Folding **: Lower case / Upper case
Lemmatization : Finding root / head word using morphology (stem words + affixes).
Stemming : Reducing to a single lemma (Porter’s algorithm)